Knowledge Graph Embedding¶
Introduction for KGE¶
A knowledge graph contains a set of entities 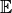 and relations
and relations 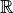 between entities.
The set of facts
between entities.
The set of facts 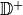 in the knowledge graph are represented in the form of triples
in the knowledge graph are represented in the form of triples 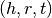 ,
where
,
where 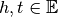 are referred to as the head (or subject) and the tail (or object) entities,
and
are referred to as the head (or subject) and the tail (or object) entities,
and 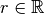 is referred to as the relationship (or predicate).
is referred to as the relationship (or predicate).
The problem of KGE is in finding a function that learns the embeddings of triples using low
dimensional vectors such that it preserves structural information, 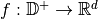 .
To accomplish this, the general principle is to enforce the learning of entities and relationships to be compatible
with the information in . The representation choices include deterministic
point, multivariate Gaussian distribution, or complex number. Under the Open World Assumption (OWA),
a set of unseen negative triplets,
.
To accomplish this, the general principle is to enforce the learning of entities and relationships to be compatible
with the information in . The representation choices include deterministic
point, multivariate Gaussian distribution, or complex number. Under the Open World Assumption (OWA),
a set of unseen negative triplets, 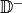 , are sampled from positive triples by
either corrupting the head or tail entity. Then, a scoring function,
, are sampled from positive triples by
either corrupting the head or tail entity. Then, a scoring function, 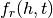 is defined to reward the
positive triples and penalize the negative triples. Finally, an optimization algorithm is used to minimize or maximize the scoring function.
is defined to reward the
positive triples and penalize the negative triples. Finally, an optimization algorithm is used to minimize or maximize the scoring function.
KGE methods are often evaluated in terms of their capability of predicting the missing entities in
negative triples 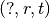 or
or 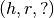 , or predicting whether an unseen fact is true or not.
The evaluation metrics include the rank of the answer in the predicted list (mean rank), and the ratio of answers
ranked top-k in the list (hit-k ratio).
, or predicting whether an unseen fact is true or not.
The evaluation metrics include the rank of the answer in the predicted list (mean rank), and the ratio of answers
ranked top-k in the list (hit-k ratio).
Implemented KGE Algorithms¶
We aim to implement as many latest state-of-the-art knowledge graph embedding methods as possible. From our perspective, by so far the KGE methods can be categorized based on the ways that how the model is trained:
Pairwise (margin) based Training KGE Models: these models utilize a latent feature of either entities or relations to explain the triples of the Knowledge graph. The features are called latent as they are not directly observed. The interaction of the entities and the relations are captured through their latent space representation. These models either utilize a distance-based scoring function or similarity-based matching function to embed the knowledge graph triples. (please refer to pykg2vec.models.pairwise for more details)
Pointwise based Training KGE Models: (please refer to pykg2vec.models.pointwise for more details).
Projection-Based (Multiclass) Training KGE Models: (please refer to pykg2vec.models.projection for more details).
Supported Dataset¶
We support various known benchmark datasets in pykg2vec.
FreebaseFB15k: Freebase dataset.
WordNet18: WordNet18 dataset.
WordNet18RR: WordNet18RR dataset.
YAGO3_10: YAGO Dataset.
DeepLearning50a: DeepLearning dataset.
We also support the use of your own dataset. Users can define their own datasets to be processed with the pykg2vec library.
Benchmarks¶
Some metrics running on benchmark dataset (FB15k) is shown below (all are filtered). We are still working on this table so it will be updated.
MR |
MRR |
Hit1 |
Hit3 |
Hit5 |
Hit10 |
|
|---|---|---|---|---|---|---|
TransE |
69.52 |
0.38 |
0.23 |
0.46 |
0.56 |
0.66 |
TransH |
77.60 |
0.32 |
0.16 |
0.41 |
0.51 |
0.62 |
TransR |
128.31 |
0.30 |
0.18 |
0.36 |
0.43 |
0.54 |
TransD |
57.73 |
0.33 |
0.19 |
0.39 |
0.48 |
0.60 |
KG2E_EL |
64.76 |
0.31 |
0.16 |
0.39 |
0.49 |
0.61 |
Complex |
96.74 |
0.65 |
0.54 |
0.74 |
0.78 |
0.82 |
DistMult |
128.78 |
0.45 |
0.32 |
0.53 |
0.61 |
0.70 |
RotatE |
48.69 |
0.74 |
0.67 |
0.80 |
0.82 |
0.86 |
SME_L |
86.3 |
0.32 |
0.20 |
0.35 |
0.43 |
0.54 |
SLM_BL |
112.65 |
0.29 |
0.18 |
0.32 |
0.39 |
0.50 |