Software Architecture and API Documentation¶
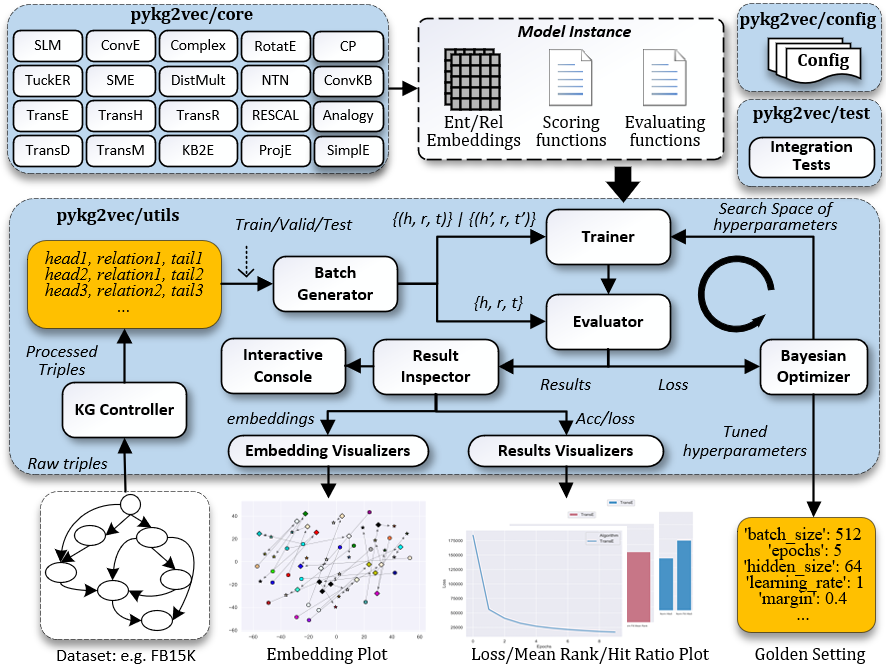
The pykg2vec is built using Python and PyTorch. It allows the computations to be assigned on both GPU and CPU. In addition to the main model training process, pykg2vec utilizes multi-processing for generating mini-batches and performing an evaluation to reduce the total execution time. The various components of the library are as follows:
KG Controller- handles all the low-level parsing tasks such as finding the total unique set of entities and relations; creating ordinal encoding maps; generating training, testing and validation triples; and caching the dataset data on disk to optimize tasks that involve repetitive model testing.Batch Generator- consists of multiple concurrent processes that manipulate and create mini-batches of data. These mini-batches are pushed to a queue to be processed by the models implemented in PyTorch or TensorFlow. The batch generator runs independently so that there is a low latency for feeding the data to the training module running on the GPU.Core Models- consists of large number of state-of-the-art KGE algorithms implemented as Python modules in PyTorch and TensorFlow. Each module consists of a modular description of the inputs, outputs, loss function,and embedding operations. Each model is provided with configuration files that define its hyperparameters.Configuration- provides the necessary configuration to parse the datasets and also consists of the baseline hyperparameters for the KGE algorithms as presented in the original research papers.Trainer and Evaluator- the Trainer module is responsible for taking an instance of the KGE model, the respective hyperparameter configuration, and input from the batch generator to train the algorithms. The Evaluator module performs link prediction and provides the respective accuracy in terms of mean ranks and filtered mean ranks.Visualization- plots training loss and common metrics used in KGE tasks. To facilitate model analysis, it also visualizes the latent representations of entities and relations on the 2D plane using t-SNE based dimensionality reduction.Bayesian Optimizer- pykg2vec uses a Bayesian hyperparameter optimizer to find a golden hyperparameter set. This feature is more efficient than brute-force based approaches.
Contents
pykg2vec¶
config.py¶
This module consists of definition of the necessary configuration parameters for all the core algorithms. The parameters are seprated into global parameters which are common across all the algorithms, and local parameters which are specific to the algorithms.
-
class
pykg2vec.config.Config(args)[source]¶ The class defines the basic configuration for the pykg2vec.
Config consists of the necessary parameter description used by all the modules including the algorithms and utility functions.
- Parameters
test_step (int) – Testing is carried out every test_step.
test_num (int) – Number of triples that will be tested during evaluation.
triple_num (int) – Number of triples that will be used for plotting the embedding.
tmp (Path Object) – Path where temporary model information is stored.
result (Path Object) – Gives the path where the result will be saved.
figures (Path Object) – Gives the path where the figures will be saved.
load_from_data (string) – If set, loads the model parameters if available from disk.
save_model (True) – If True, store the trained model parameters.
disp_summary (bool) – If True, display the summary before and after training the algorithm.
disp_result (bool) – If True, displays result while training.
plot_embedding (bool) – If True, will plot the embedding after performing t-SNE based dimensionality reduction.
log_training_placement (bool) – If True, allows us to find out which devices the operations and tensors are assigned to.
plot_training_result (bool) – If True, plots the loss values stored during training.
plot_testing_result (bool) – If True, it will plot all the testing result such as mean rank, hit ratio, etc.
plot_entity_only (bool) – If True, plots the t-SNE reduced embdding of the entities in a figure.
hits (List) – Gives the list of integer for calculating hits.
knowledge_graph (Object) – It prepares and holds the instance of the knowledge graph dataset.
kg_meta (object) – Stores the statistics metadata of the knowledge graph.
pykg2vec.data¶
pykg2vec.data.kgcontroller¶
This module is for controlling knowledge graph
-
class
pykg2vec.data.kgcontroller.KGMetaData(tot_entity=None, tot_relation=None, tot_triple=None, tot_train_triples=None, tot_test_triples=None, tot_valid_triples=None)[source]¶ The class store the metadata of the knowledge graph.
Instance of KGMetaData is used later to build the algorithms based of number of entities and relation.
- Parameters
tot_entity (int) – Total number of combined head and tail entities present in knowledge graph.
tot_relation (int) – Total number of relations present in knowlege graph.
tot_triple (int) – Total number of head, relation and tail (triples) present in knowledge graph.
tot_train_triples (int) – Total number of training triples
tot_test_triples (int) – Total number of testing triple
tot_valid_triples (int) – Total number of validation triples
Examples
>>> from pykg2vec.data.kgcontroller import KGMetaData >>> kg_meta = KGMetaData(tot_triple =1000)
-
class
pykg2vec.data.kgcontroller.KnowledgeGraph(dataset='Freebase15k', custom_dataset_path=None)[source]¶ The class is the main module that handles the knowledge graph.
KnowledgeGraph is responsible for downloading, parsing, processing and preparing the training, testing and validation dataset.
- Parameters
Examples
>>> from pykg2vec.data.kgcontroller import KnowledgeGraph >>> knowledge_graph = KnowledgeGraph(dataset='Freebase15k') >>> knowledge_graph.prepare_data()
-
read_hr_t_train()[source]¶ Function to read the list of tails for the given head and relation pair for the training set.
-
read_hr_t_valid()[source]¶ Function to read the list of tails for the given head and relation pair for the valid set.
-
read_relation_property()[source]¶ Function to read the relation property.
- Returns
Returns the list of relation property.
- Return type
-
read_tr_h_train()[source]¶ Function to read the list of heads for the given tail and relation pair for the training set.
-
read_tr_h_valid()[source]¶ Function to read the list of heads for the given tail and relation pair for the valid set.
-
class
pykg2vec.data.kgcontroller.Triple(h, r, t)[source]¶ The class defines the datastructure of the knowledge graph triples.
Triple class is used to store the head, tail and relation triple in both its numerical id and string form. It also stores the dictonary of (head, relation)=[tail1, tail2,..] and (tail, relation)=[head1, head2, …]
- Parameters
Examples
>>> from pykg2vec.data.kgcontroller import Triple >>> trip1 = Triple(2,3,5) >>> trip2 = Triple('Tokyo','isCapitalof','Japan')
pykg2vec.data.generator¶
This module is for generating the batch data for training and testing.
-
class
pykg2vec.data.generator.Generator(model, config)[source]¶ Generator class for the embedding algorithms
- Parameters
- Yields
matrix – Batch size of processed triples
Examples
>>> from pykg2vec.utils.generator import Generator >>> from pykg2vec.models.TransE impor TransE >>> model = TransE() >>> gen_train = Generator(model.config, training_strategy=TrainingStrategy.PAIRWISE_BASED)
-
pykg2vec.data.generator.process_function_multiclass(raw_queue, processed_queue, config)[source]¶ Function that puts the processed data in the queue.
- Parameters
raw_queue (Queue) – Multiprocessing Queue to put the raw data to be processed.
processed_queue (Queue) – Multiprocessing Queue to put the processed data.
config (pykg2vec.Config) – Consists of the necessary parameters for training configuration.
-
pykg2vec.data.generator.process_function_pairwise(raw_queue, processed_queue, config)[source]¶ Function that puts the processed data in the queue.
- Parameters
raw_queue (Queue) – Multiprocessing Queue to put the raw data to be processed.
processed_queue (Queue) – Multiprocessing Queue to put the processed data.
config (pykg2vec.Config) – Consists of the necessary parameters for training configuration.
-
pykg2vec.data.generator.process_function_pointwise(raw_queue, processed_queue, config)[source]¶ Function that puts the processed data in the queue.
- Parameters
raw_queue (Queue) – Multiprocessing Queue to put the raw data to be processed.
processed_queue (Queue) – Multiprocessing Queue to put the processed data.
config (pykg2vec.Config) – Consists of the necessary parameters for training configuration.
-
pykg2vec.data.generator.raw_data_generator(command_queue, raw_queue, config)[source]¶ Function to feed triples to raw queue for multiprocessing.
- Parameters
command_queue (Queue) – Each enqueued is either a command or a number of batch size.
raw_queue (Queue) – Multiprocessing Queue to put the raw data to be processed.
config (pykg2vec.Config) – Consists of the necessary parameters for training configuration.
pykg2vec.data.datasets¶
-
class
pykg2vec.data.datasets.DeepLearning50a[source]¶ This data structure defines the necessary information for downloading DeepLearning50a dataset.
DeepLearning50a module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.FreebaseFB15k[source]¶ This data structure defines the necessary information for downloading Freebase dataset.
FreebaseFB15k module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.FreebaseFB15k_237[source]¶ This data structure defines the necessary information for downloading FB15k-237 dataset.
FB15k-237 module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.Kinship[source]¶ This data structure defines the necessary information for downloading Kinship dataset.
Kinship module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.KnownDataset(name, url, prefix)[source]¶ The class consists of modules to handle the known datasets.
There are various known knowledge graph datasets used by the research community. These datasets maybe in different format. This module helps in parsing those known datasets for training and testing the algorithms.
- Parameters
Examples
>>> from pykg2vec.data.kgcontroller import KnownDataset >>> name = "dL50a" >>> url = "https://github.com/louisccc/KGppler/raw/master/datasets/dL50a.tgz" >>> prefix = 'deeplearning_dataset_50arch-' >>> kgdata = KnownDataset(name, url, prefix) >>> kgdata.download() >>> kgdata.extract() >>> kgdata.dump()
-
class
pykg2vec.data.datasets.NELL_995[source]¶ This data structure defines the necessary information for downloading NELL-995 dataset.
NELL-995 module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.Nations[source]¶ This data structure defines the necessary information for downloading Nations dataset.
Nations module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.UMLS[source]¶ This data structure defines the necessary information for downloading UMLS dataset.
UMLS module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.UserDefinedDataset(name, custom_dataset_path)[source]¶ The class consists of modules to handle the user defined datasets.
User may define their own datasets to be processed with the pykg2vec library.
- Parameters
name (str) – Name of the datasets
-
class
pykg2vec.data.datasets.WordNet18[source]¶ This data structure defines the necessary information for downloading WordNet18 dataset.
WordNet18 module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.WordNet18_RR[source]¶ This data structure defines the necessary information for downloading WordNet18_RR dataset.
WordNet18_RR module inherits the KnownDataset class for processing the knowledge graph dataset.
-
class
pykg2vec.data.datasets.YAGO3_10[source]¶ This data structure defines the necessary information for downloading YAGO3_10 dataset.
YAGO3_10 module inherits the KnownDataset class for processing the knowledge graph dataset.
-
pykg2vec.data.datasets.extract_tar(tar_path, extract_path='.')[source]¶ This function extracts the tar file.
Most of the knowledge graph datasets are downloaded in a compressed tar format. This function is used to extract them
pykg2vec.models¶
pykg2vec.models.pairwise¶
-
class
pykg2vec.models.pairwise.HoLE(**kwargs)[source]¶ Holographic Embeddings of Knowledge Graphs. (HoLE) employs the circular correlation to create composition correlations. It is able to represent and capture the interactions betweek entities and relations while being efficient to compute, easier to train and scalable to large dataset.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.KG2E(**kwargs)[source]¶ Learning to Represent Knowledge Graphs with Gaussian Embedding (KG2E) Instead of assumming entities and relations as determinstic points in the embedding vector spaces, KG2E models both entities and relations (h, r and t) using random variables derived from multivariate Gaussian distribution. KG2E then evaluates a fact using translational relation by evaluating the distance between two distributions, r and t-h. KG2E provides two distance measures (KL-divergence and estimated likelihood). Portion of the code based on mana-ysh’s repository.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.NTN(**kwargs)[source]¶ Reasoning With Neural Tensor Networks for Knowledge Base Completion (NTN) is a neural tensor network which represents entities as an average of their constituting word vectors. It then projects entities to their vector embeddings in the input layer. The two entities are then combined and mapped to a non-linear hidden layer. https://github.com/siddharth-agrawal/Neural-Tensor-Network/blob/master/neuralTensorNetwork.py It is a neural tensor network which represents entities as an average of their constituting word vectors. It then projects entities to their vector embeddings in the input layer. The two entities are then combined and mapped to a non-linear hidden layer. Portion of the code based on siddharth-agrawal.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.Rescal(**kwargs)[source]¶ A Three-Way Model for Collective Learning on Multi-Relational Data (RESCAL) is a tensor factorization approach to knowledge representation learning, which is able to perform collective learning via the latent components of the factorization. Rescal is a latent feature model where each relation is represented as a matrix modeling the iteraction between latent factors. It utilizes a weight matrix which specify how much the latent features of head and tail entities interact in the relation. Portion of the code based on mnick and OpenKE_Rescal.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.RotatE(**kwargs)[source]¶ Rotate-Knowledge graph embedding by relation rotation in complex space (RotatE) models the entities and the relations in the complex vector space. The translational relation in RotatE is defined as the element-wise 2D rotation in which the head entity h will be rotated to the tail entity t by multiplying the unit-length relation r in complex number form.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.SLM(**kwargs)[source]¶ In Reasoning With Neural Tensor Networks for Knowledge Base Completion, SLM model is designed as a baseline of Neural Tensor Network. The model constructs a nonlinear neural network to represent the score function.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.SME(**kwargs)[source]¶ A Semantic Matching Energy Function for Learning with Multi-relational Data
Semantic Matching Energy (SME) is an algorithm for embedding multi-relational data into vector spaces. SME conducts semantic matching using neural network architectures. Given a fact (h, r, t), it first projects entities and relations to their embeddings in the input layer. Later the relation r is combined with both h and t to get gu(h, r) and gv(r, t) in its hidden layer. The score is determined by calculating the matching score of gu and gv.
There are two versions of SME: a linear version(SMELinear) as well as bilinear(SMEBilinear) version which differ in how the hidden layer is defined.
- Parameters
config (object) – Model configuration parameters.
Portion of the code based on glorotxa.
-
class
pykg2vec.models.pairwise.SME_BL(**kwargs)[source]¶ A Semantic Matching Energy Function for Learning with Multi-relational Data
SME_BL is an extension of SME that BiLinear function to calculate the matching scores.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.TransD(**kwargs)[source]¶ Knowledge Graph Embedding via Dynamic Mapping Matrix (TransD) is an improved version of TransR. For each triplet
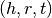 , it uses two mapping matrices
, it uses two mapping matrices 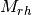 ,
, 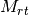
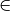
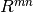 to project entities from entity space to relation space.
TransD constructs a dynamic mapping matrix for each entity-relation pair by considering the diversity of entities and relations simultaneously.
Compared with TransR/CTransR, TransD has fewer parameters and has no matrix vector multiplication.
to project entities from entity space to relation space.
TransD constructs a dynamic mapping matrix for each entity-relation pair by considering the diversity of entities and relations simultaneously.
Compared with TransR/CTransR, TransD has fewer parameters and has no matrix vector multiplication.- Parameters
config (object) – Model configuration parameters.
Portion of the code based on OpenKE_TransD.
-
class
pykg2vec.models.pairwise.TransE(**kwargs)[source]¶ Translating Embeddings for Modeling Multi-relational Data (TransE) is an energy based model which represents the relationships as translations in the embedding space. Specifically, it assumes that if a fact (h, r, t) holds then the embedding of the tail ‘t’ should be close to the embedding of head entity ‘h’ plus some vector that depends on the relationship ‘r’. Which means that if (h,r,t) holds then the embedding of the tail ‘t’ should be close to the embedding of head entity ‘h’ plus some vector that depends on the relationship ‘r’. In TransE, both entities and relations are vectors in the same space
- Parameters
config (object) – Model configuration parameters.
Portion of the code based on OpenKE_TransE and wencolani.
-
class
pykg2vec.models.pairwise.TransH(**kwargs)[source]¶ Knowledge Graph Embedding by Translating on Hyperplanes (TransH) follows the general principle of the TransE. However, compared to it, it introduces relation-specific hyperplanes. The entities are represented as vecotrs just like in TransE, however, the relation is modeled as a vector on its own hyperplane with a normal vector. The entities are then projected to the relation hyperplane to calculate the loss. TransH models a relation as a hyperplane together with a translation operation on it. By doing this, it aims to preserve the mapping properties of relations such as reflexive, one-to-many, many-to-one, and many-to-many with almost the same model complexity of TransE.
- Parameters
config (object) – Model configuration parameters.
Portion of the code based on OpenKE_TransH and thunlp_TransH.
-
class
pykg2vec.models.pairwise.TransM(**kwargs)[source]¶ Transition-based Knowledge Graph Embedding with Relational Mapping Properties (TransM) is another line of research that improves TransE by relaxing the overstrict requirement of h+r ==> t. TransM associates each fact (h, r, t) with a weight theta(r) specific to the relation. TransM helps to remove the the lack of flexibility present in TransE when it comes to mapping properties of triplets. It utilizes the structure of the knowledge graph via pre-calculating the distinct weight for each training triplet according to its relational mapping property.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pairwise.TransR(**kwargs)[source]¶ Learning Entity and Relation Embeddings for Knowledge Graph Completion (TransR) is a translation based knowledge graph embedding method. Similar to TransE and TransH, it also builds entity and relation embeddings by regarding a relation as translation from head entity to tail entity. However, compared to them, it builds the entity and relation embeddings in a separate entity and relation spaces. Portion of the code based on thunlp_transR.
- Parameters
config (object) – Model configuration parameters.
pykg2vec.models.pointwise¶
-
class
pykg2vec.models.pointwise.ANALOGY(**kwargs)[source]¶ Analogical Inference for Multi-relational Embeddings
- Parameters
config (object) – Model configuration parameters.
-
embed(h, r, t)[source]¶ Function to get the embedding value.
- Parameters
h (Tensor) – Head entities ids.
r (Tensor) – Relation ids of the triple.
t – Tail entity ids of the triple.
-
class
pykg2vec.models.pointwise.CP(**kwargs)[source]¶ Canonical Tensor Decomposition for Knowledge Base Completion
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.Complex(**kwargs)[source]¶ Complex Embeddings for Simple Link Prediction (ComplEx) is an enhanced version of DistMult in that it uses complex-valued embeddings to represent both entities and relations. Using the complex-valued embedding allows the defined scoring function in ComplEx to differentiate that facts with assymmetric relations.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.ComplexN3(**kwargs)[source]¶ Complex Embeddings for Simple Link Prediction (ComplEx) is an enhanced version of DistMult in that it uses complex-valued embeddings to represent both entities and relations. Using the complex-valued embedding allows the defined scoring function in ComplEx to differentiate that facts with assymmetric relations.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.ConvKB(**kwargs)[source]¶ In A Novel Embedding Model for Knowledge Base Completion Based on Convolutional Neural Network (ConvKB), each triple (head entity, relation, tail entity) is represented as a 3-column matrix where each column vector represents a triple element
Portion of the code based on daiquocnguyen.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.DistMult(**kwargs)[source]¶ EMBEDDING ENTITIES AND RELATIONS FOR LEARNING AND INFERENCE IN KNOWLEDGE BASES (DistMult) is a simpler model comparing with RESCAL in that it simplifies the weight matrix used in RESCAL to a diagonal matrix. The scoring function used DistMult can capture the pairwise interactions between the head and the tail entities. However, DistMult has limitation on modeling asymmetric relations.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.MuRP(**kwargs)[source]¶ Multi-relational Poincaré Graph Embeddings
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.OctonionE(**kwargs)[source]¶ Quaternion Knowledge Graph Embeddings
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.QuatE(**kwargs)[source]¶ Quaternion Knowledge Graph Embeddings
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.SimplE(**kwargs)[source]¶ SimplE Embedding for Link Prediction in Knowledge Graphs
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.pointwise.SimplE_ignr(**kwargs)[source]¶ SimplE Embedding for Link Prediction in Knowledge Graphs
- Parameters
config (object) – Model configuration parameters.
pykg2vec.models.projection¶
-
class
pykg2vec.models.projection.AcrE(**kwargs)[source]¶ Knowledge Graph Embedding with Atrous Convolution and Residual Learning
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.projection.ConvE(**kwargs)[source]¶ Convolutional 2D Knowledge Graph Embeddings (ConvE) is a multi-layer convolutional network model for link prediction, it is a embedding model which is highly parameter efficient. ConvE is the first non-linear model that uses a global 2D convolution operation on the combined and head entity and relation embedding vectors. The obtained feature maps are made flattened and then transformed through a fully connected layer. The projected target vector is then computed by performing linear transformation (passing through the fully connected layer) and activation function, and finally an inner product with the latent representation of every entities.
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.projection.HypER(**kwargs)[source]¶ HypER: Hypernetwork Knowledge Graph Embeddings
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.projection.InteractE(**kwargs)[source]¶ InteractE: Improving Convolution-based Knowledge Graph Embeddings by Increasing Feature Interactions
- Parameters
config (object) – Model configuration parameters.
-
class
pykg2vec.models.projection.ProjE_pointwise(**kwargs)[source]¶ ProjE-Embedding Projection for Knowledge Graph Completion. (ProjE) Instead of measuring the distance or matching scores between the pair of the head entity and relation and then tail entity in embedding space ((h,r) vs (t)). ProjE projects the entity candidates onto a target vector representing the input data. The loss in ProjE is computed by the cross-entropy between the projected target vector and binary label vector, where the included entities will have value 0 if in negative sample set and value 1 if in positive sample set. Instead of measuring the distance or matching scores between the pair of the head entity and relation and then tail entity in embedding space ((h,r) vs (t)). ProjE projects the entity candidates onto a target vector representing the input data. The loss in ProjE is computed by the cross-entropy between the projected target vector and binary label vector, where the included entities will have value 0 if in negative sample set and value 1 if in positive sample set.
- Parameters
config (object) – Model configuration parameters.
-
f1(h, r)[source]¶ Defines froward layer for head.
- Parameters
h (Tensor) – Head entities ids.
r (Tensor) – Relation ids of the triple.
-
f2(t, r)[source]¶ Defines forward layer for tail.
- Parameters
t (Tensor) – Tail entities ids.
r (Tensor) – Relation ids of the triple.
-
class
pykg2vec.models.projection.TuckER(**kwargs)[source]¶ TuckER-Tensor Factorization for Knowledge Graph Completion (TuckER) is a Tensor-factorization-based embedding technique based on the Tucker decomposition of a third-order binary tensor of triplets. Although being fully expressive, the number of parameters used in Tucker only grows linearly with respect to embedding dimension as the number of entities or relations in a knowledge graph increases. TuckER is a Tensor-factorization-based embedding technique based on the Tucker decomposition of a third-order binary tensor of triplets. Although being fully expressive, the number of parameters used in Tucker only grows linearly with respect to embedding dimension as the number of entities or relations in a knowledge graph increases. The author also showed in paper that the models, such as RESCAL, DistMult, ComplEx, are all special case of TuckER.
- Parameters
config (object) – Model configuration parameters.
pykg2vec.models.Domain¶
Domain module for building Knowledge Graphs
pykg2vec.models.KGMeta¶
Knowledge Graph Meta Class¶
It provides Abstract class for the Knowledge graph models.
-
class
pykg2vec.models.KGMeta.PairwiseModel(model_name)[source]¶ Meta Class for KGE models with translational distance
pykg2vec.utils¶
pykg2vec.utils.bayesian_optimizer¶
This module is for performing bayesian optimization on algorithms
-
class
pykg2vec.utils.bayesian_optimizer.BaysOptimizer(args)[source]¶ Bayesian optimizer class for tuning hyperparameter.
This class implements the Bayesian Optimizer for tuning the hyper-parameter.
- Parameters
Examples
>>> from pykg2vec.common import KGEArgParser >>> from pykg2vec.utils.bayesian_optimizer import BaysOptimizer >>> model = Complex() >>> args = KGEArgParser().get_args(sys.argv[1:]) >>> bays_opt = BaysOptimizer(args=args) >>> bays_opt.optimize()
pykg2vec.utils.criterion¶
-
class
pykg2vec.utils.criterion.Criterion[source]¶ Utility for calculating KGE losses
Loss Functions in Knowledge Graph Embedding Models http://ceur-ws.org/Vol-2377/paper_1.pdf
pykg2vec.utils.evaluator¶
This module is for evaluating the results
-
class
pykg2vec.utils.evaluator.Evaluator(model, config, tuning=False)[source]¶ Class to perform evaluation of the model.
Examples
>>> from pykg2vec.utils.evaluator import Evaluator >>> evaluator = Evaluator(model=model, tuning=True) >>> evaluator.test_batch(Session(), 0) >>> acc = evaluator.output_queue.get() >>> evaluator.stop()
-
class
pykg2vec.utils.evaluator.MetricCalculator(config)[source]¶ MetricCalculator aims to 1) address all the statistic tasks. 2) provide interfaces for querying results.
MetricCalculator is expected to be used by “evaluation_process”.
pykg2vec.utils.riemannian_optimizer¶
pykg2vec.utils.trainer¶
-
class
pykg2vec.utils.trainer.EarlyStopper(patience, monitor)[source]¶ Class used by trainer for handling the early stopping mechanism during the training of KGE algorithms.
- Parameters
patience (int) – Number of epochs to wait before early stopping the training on no improvement.
early stopping if it is a negative number (default (No) – {-1}).
monitor (Monitor) – the type of metric that earlystopper will monitor.
-
class
pykg2vec.utils.trainer.Trainer(model, config)[source]¶ Class for handling the training of the algorithms.
- Parameters
model (object) – KGE model object
Examples
>>> from pykg2vec.utils.trainer import Trainer >>> from pykg2vec.models.pairwise import TransE >>> trainer = Trainer(TransE()) >>> trainer.build_model() >>> trainer.train_model()
-
export_embeddings()[source]¶ Export embeddings in tsv and pandas pickled format. With tsvs (both label, vector files), you can: 1) Use those pretained embeddings for your applications. 2) Visualize the embeddings in this website to gain insights. (https://projector.tensorflow.org/)
Pandas dataframes can be read with pd.read_pickle(‘desired_file.pickle’)
pykg2vec.utils.visualization¶
This module is for visualizing the results
-
class
pykg2vec.utils.visualization.Visualization(model, config, vis_opts=None)[source]¶ Class to aid in visualizing the results and embddings.
- Parameters
Examples
>>> from pykg2vec.utils.visualization import Visualization >>> from pykg2vec.utils.trainer import Trainer >>> from pykg2vec.models.TransE import TransE >>> model = TransE() >>> trainer = Trainer(model=model) >>> trainer.build_model() >>> trainer.train_model() >>> viz = Visualization(model=model) >>> viz.plot_train_result()
-
static
draw_embedding(embs, names, resultpath, algos, show_label)[source]¶ Function to draw the embedding.
-
static
draw_embedding_rel_space(h_emb, r_emb, t_emb, h_name, r_name, t_name, resultpath, algos, show_label)[source]¶ Function to draw the embedding in relation space.
- Parameters
h_emb (matrix) – Two dimesnional embeddings of head.
r_emb (matrix) – Two dimesnional embeddings of relation.
t_emb (matrix) – Two dimesnional embeddings of tail.
h_name (list) – List of string name of the head.
r_name (list) – List of string name of the relation.
t_name (list) – List of string name of the tail.
resultpath (str) – Path where the result will be save.
algos (str) – Name of the algorithms which generated the algorithm.
show_label (bool) – If True, prints the string names of the entities and relations.
pykg2vec.test¶
After installation, you can use pytest to run the test suite from pykg2vec’s root directory:
pytest
pykg2vec.test.test_generator¶
This module is for testing unit functions of generator
-
pykg2vec.test.test_generator.test_generator_pairwise()[source]¶ Function to test the generator for pairwise based algorithm.
pykg2vec.test.test_hp_loader¶
This module is for testing unit functions of the hyperparameter loader
pykg2vec.test.test_inference¶
This module is for testing unit functions of model
pykg2vec.test.test_kg¶
This module is for testing unit functions of KnowledgeGraph
pykg2vec.test.test_logger¶
This module is for testing unit functions of Logger
pykg2vec.test.test_model¶
This module is for testing unit functions of model
pykg2vec.test.test_trainer¶
This module is for testing unit functions of training
pykg2vec.test.test_tune_model¶
This module is for testing unit functions of tuning model
-
pykg2vec.test.test_tune_model.test_return_empty_before_optimization(mocked_fmin)[source]¶ Function to test the tuning of the models.
pykg2vec.test.test_inference¶
This module is for integration tests on visualization